記憶體管理中的堆更像是一個池。 有StackOverflow 上的討論,我們不談論這個不同的細節。你知道我們談論演算法和資料結構中的堆概念對我們來說就足夠了。我們依然沿襲的風格演算法簡介。堆是用陣列表示的完全二元樹。二元樹是樹的一種,每個父節點最多有兩個子節點,我們稱為左子樹和右子樹。
完美二元樹是層數為k時的二元樹,它有2層k
-1 個節點。像這樣:我們可以認為完全二元樹是完美的二元樹洩漏或不是缺少某些節點但必須從上到下、從左到右填充節點。
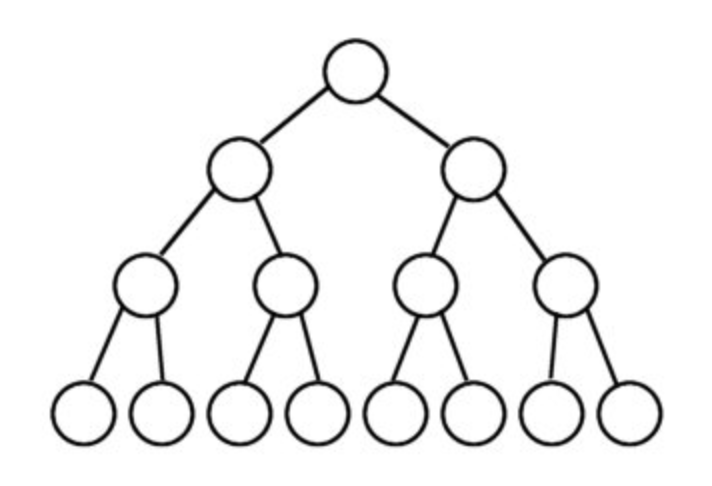
這意味著只能從右側缺少一些節點。像這樣:
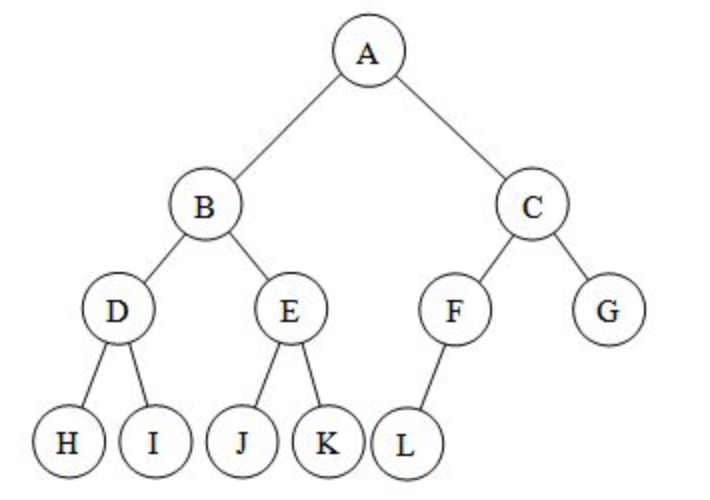
當我們用堆來儲存這棵完整的二元樹時,我們可以將它保存為這樣的陣列:[A, B, C, D, E, F, G, H, I, J, K, L]。使用這種儲存方式,我們會發現這棵樹的根索引為1。
每個父節點的索引是子節點的索引除以2。
這樣我們就得到了存取子節點和父節點的函數。

然後我們討論一個資料結構,Max-Heap。它是一堆,每個父母都比它的孩子大。所以我們知道Max-Heap中root是最大的數。上圖是一個Max-Heap及其對應的陣列。
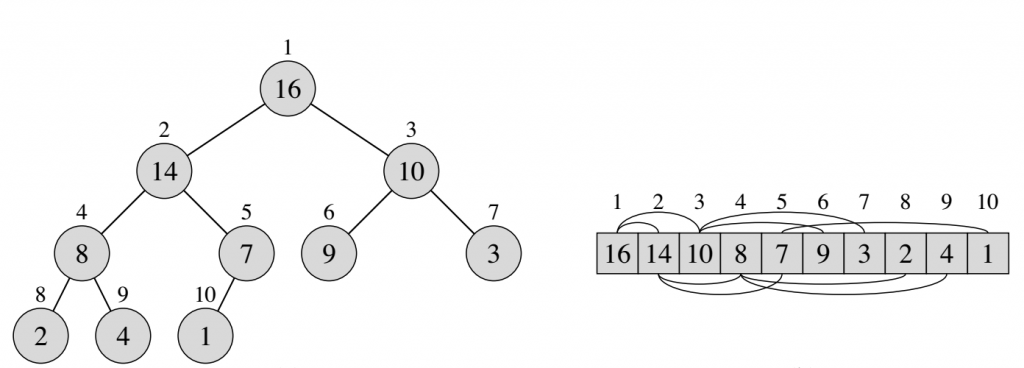
您可以輕鬆定義最小堆,我們現在不討論它。
如果a的一個節點最大堆小於其子節點,違反了最大堆規則。如果我們知道它的子節點是有效的最大堆,我們可以透過最大堆化手術。步驟是我們比較這個節點和它的子節點的值,誰最大,如果不是父節點,我們將最大的子節點與父節點交換。然後我們檢查子節點及其子節點。一步一步,我們可以確定操作後最大堆變得有效。
我們做了一個影片演示,4是錯誤節點。
這是代碼。_A 是儲存堆的數組,索引為 -1,因為在 Java 中數組的索引從 0 開始:

為了運行 Max-Heapify,我們編寫了一個輔助函數交換:

那我們要如何從隨機完全二元樹建立最大堆呢?假設我們有一個這樣的堆:
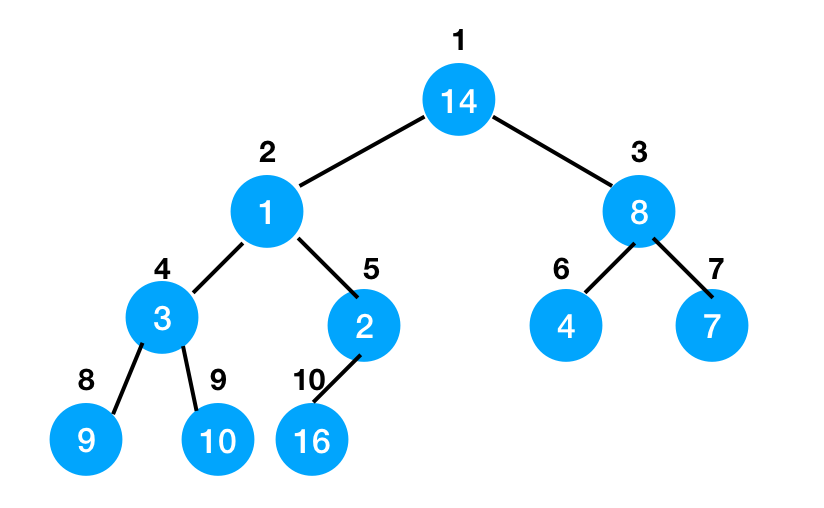
我們可以從堆的中間(第5個節點)開始,逐一回到根節點來執行max-heapify操作。完成後,我們就有了一個最大堆。這是一個示範影片:
程式碼如下:

當我們仔細觀察時,我們會發現最大堆並不是一個有序的資料結構。每個父節點都比其子節點大,但左子節點可以大於也可以小於右子節點。我們無法僅透過以任何方式遍歷二元樹來輕鬆獲得有序數組。那我們要如何使用堆來對數字進行排序呢?
我們知道根永遠是最大的。因此我們可以將根與最後一個節點交換,然後從堆中刪除最後一個節點,並對根進行最大堆化。然後剩餘的堆就成為有效的最大堆,我們可以一次又一次地這樣做。我們總是把最大的數放在後面,這樣我們就得到了一個有序數組。
我們可以從這個max-heap開始進行排序。

這是我們的示範影片:
程式碼如下:

並且 max-heap 可以支援一個操作提取最大,返回根,刪除它,並收縮堆。我們可以用它來取得最大數或k最大的數,而不用先排序。程式碼如下:

所以我們可以使用 max-heap 來對數字進行排序。或者我們可以用它來取得最大數或取得第 k 個最大的數,從而比排序花費更少的成本。
GitHub地址······https://github.com/tinyfool/leetcode/blob/master/src/CLRS/HeapSort.java
LeetCode 與堆和堆排序相關的問題:
