मेमोरी प्रबंधन में हीप एक पूल की तरह है। वहाँ हैStackOverflow पर एक चर्चा, हम इस अलग के विवरण के बारे में बात नहीं करते हैं।आप जानते हैं कि हम एल्गोरिदम में हीप अवधारणा के बारे में बात कर रहे हैं और डेटा संरचना हमारे लिए पर्याप्त है।हम अभी भी की शैली का पालन करते हैंएल्गोरिदम का परिचय.हीप एक संपूर्ण बाइनरी ट्री है जिसे एक सरणी द्वारा दर्शाया जाता है।बाइनरी ट्री एक प्रकार का पेड़ है, प्रत्येक मूल नोड में अधिकतम दो बच्चे होते हैं, हम उन्हें बाएँ-उपवृक्ष और दाएँ-उपवृक्ष कहते हैं।
एक आदर्श बाइनरी ट्री एक बाइनरी ट्री होता है जब परत संख्या k होती है, इसमें 2 होता हैके
-1 नोड्स.इस कदर:और हम सोच सकते हैं कि एक पूर्ण बाइनरी ट्री एक आदर्श बाइनरी ट्री लीक है या इसमें कुछ नोड्स की कमी नहीं है, लेकिन नोड्स को ऊपर से नीचे, बाएं से दाएं भरना होगा।
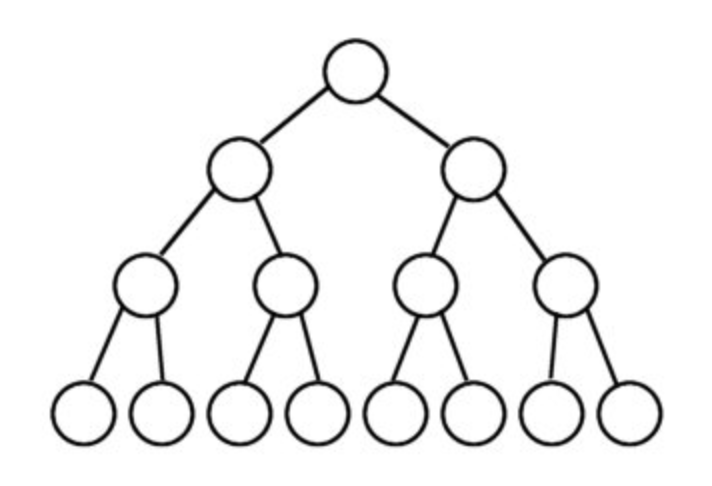
इसका मतलब है कि दाईं ओर से केवल कुछ नोड्स की कमी हो सकती है।इस कदर:
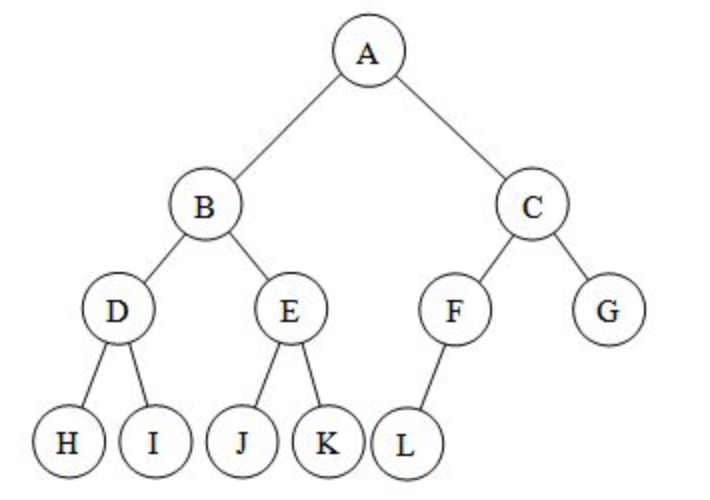
जब हम इस संपूर्ण बाइनरी ट्री को संग्रहीत करने के लिए एक ढेर का उपयोग करते हैं, तो हम इसे इस तरह एक सरणी के रूप में सहेज सकते हैं: [ए, बी, सी, डी, ई, एफ, जी, एच, आई, जे, के, एल]।इस भंडारण विधि का उपयोग करें, हम पाएंगे कि इस पेड़ की जड़ का सूचकांक 1 है।
और प्रत्येक मूल नोड का सूचकांक बच्चों के नोड का सूचकांक 2 से विभाजित होता है। और बाएं उप-नोड का सूचकांक इसका मूल नोड का सूचकांक 2 से गुणा होता है, दाएं उप-नोड का सूचकांक इसका मूल भाग होता हैनोड के सूचकांक को 2 से गुणा करें फिर 1 जोड़ें।
तो हमें बच्चों और पैरेंट नोड्स तक पहुंचने का फ़ंक्शन मिलता है।

फिर हम डेटा संरचना, मैक्स-हीप पर चर्चा करते हैं।यह एक ढेर है, हर माता-पिता अपने बच्चों से बड़े हैं।तो हम जानते हैं कि मैक्स-हीप में रूट सबसे बड़ी संख्या है।चित्र एक मैक्स-हीप और उसके अनुरूप सरणी है।
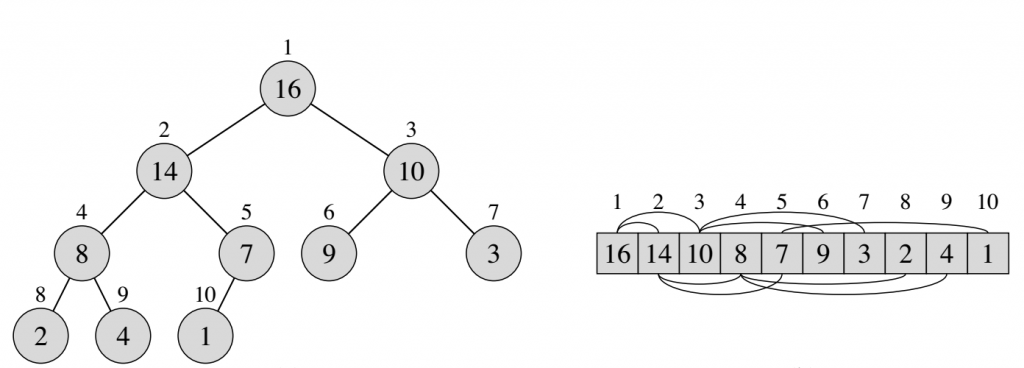
आप मिन-हीप को आसानी से परिभाषित कर सकते हैं, हम अभी इस पर चर्चा नहीं करते हैं।
यदि a का एक नोडअधिकतम-ढेरअपने उप-नोड्स से छोटा, यह अधिकतम-हीप के नियम का उल्लंघन करता है।यदि हम जानते हैं कि इसका उप-नोड्स वैध अधिकतम-हीप है, तो हम इसे a द्वारा सही कर सकते हैंअधिकतम-ढेरीकरणसंचालन।चरणों में हम इस नोड और उसके बच्चों के मूल्य की तुलना करते हैं, जो सबसे बड़ा है, यदि मूल नोड नहीं है, तो हम मूल नोड के साथ सबसे बड़े उप-नोड को स्वैप करते हैं।फिर हम उप-नोड की उसके बच्चों के साथ जांच करते हैं।कदम दर कदम, हम यह सुनिश्चित कर सकते हैं कि ऑपरेशन के बाद मैक्स-हीप वैध हो जाए।
हम एक वीडियो डेमो बनाते हैं, 4 त्रुटि नोड है।
यह कोड है._A सरणी को ढेर में संग्रहित करता है, और सूचकांक -1 है क्योंकि जावा सरणी में सूचकांक 0 से शुरू होता है:

Max-Heapify को चलाने के लिए, हम एक सहायक फ़ंक्शन एक्सचेंज लिखते हैं:

तो फिर हम एक यादृच्छिक पूर्ण बाइनरी ट्री से मैक्स-हीप कैसे बना सकते हैं?मान लीजिए हमारे पास इस तरह का ढेर है:
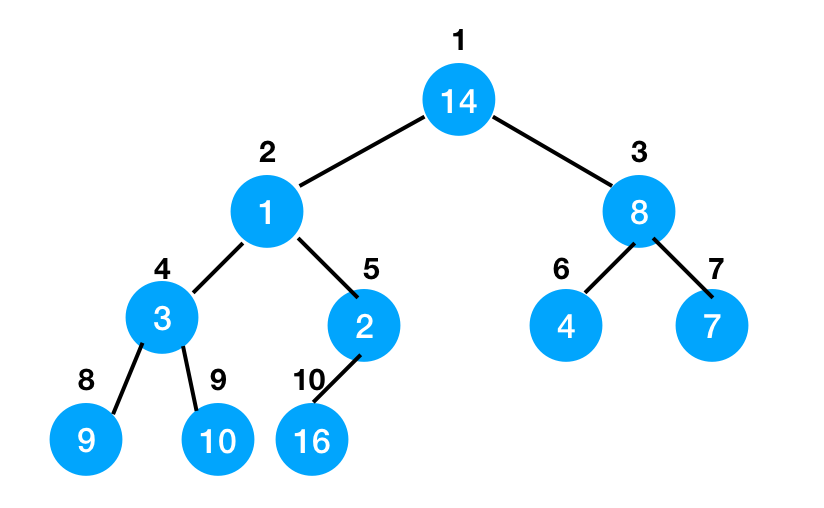
हम मैक्स-हीपिफाई ऑपरेशन करने के लिए ढेर के मध्य (पांचवें नोड) से शुरू कर सकते हैं, एक-एक करके रूट पर वापस आ सकते हैं।जब यह समाप्त हो गया, तो हमारे पास अधिकतम-ढेर होगा।इसके लिए यह एक डेमो वीडियो है:
कोड इस प्रकार:

जब हम ध्यान से देखेंगे तो पाएंगे कि मैक्स-हीप एक ऑर्डर की गई डेटा संरचना नहीं है।प्रत्येक मूल नोड अपने बच्चों से बड़ा होता है, लेकिन बायाँ उप-नोड बड़ा हो सकता है और दाएँ उप-नोड से छोटा भी हो सकता है।हम किसी भी तरह से बाइनरी ट्री को पार करके आसानी से एक ऑर्डर किया हुआ ऐरे प्राप्त नहीं कर सकते।तो हम संख्याओं को क्रमबद्ध करने के लिए ढेर का उपयोग कैसे करते हैं?
हम जानते हैं कि जड़ हमेशा सबसे बड़ी होती है।तो हम रूट को अंतिम नोड के साथ स्वैप कर सकते हैं, फिर अंतिम नोड को ढेर से हटा सकते हैं, और रूट को अधिकतम-हीपाइज़ कर सकते हैं।फिर शेष ढेर एक वैध अधिकतम-ढेर बन जाता है, हम इसे बार-बार कर सकते हैं।हम हमेशा सबसे बड़ी संख्या को पीछे रखते हैं, इसलिए हमें एक क्रमबद्ध सरणी मिलती है।
हम सॉर्ट करने के लिए इस अधिकतम-ढेर से शुरुआत कर सकते हैं।

और यह हमारा डेमो वीडियो है:
कोड इस प्रकार:

और मैक्स-हीप एक ऑपरेशन का समर्थन कर सकता हैएक्स्ट्रैक्टमैक्स, जड़ को लौटाएं, हटाएं और ढेर को सिकोड़ें।हम इसका उपयोग पहले क्रमबद्ध किए बिना अधिकतम संख्या या k सबसे बड़ी संख्या प्राप्त करने के लिए कर सकते हैं।कोड इस प्रकार:

इसलिए हम संख्याओं को क्रमबद्ध करने के लिए मैक्स-हीप का उपयोग कर सकते हैं।या हम इसका उपयोग अधिकतम संख्या प्राप्त करने के लिए कर सकते हैं या इसे क्रमबद्ध करने की तुलना में कम लागत का भुगतान करने के लिए k सबसे बड़ी संख्या प्राप्त कर सकते हैं।
GitHub पताï¼https://github.com/tinyfool/leetcode/blob/master/src/CLRS/HeapSort.java
हीप और हीप-सॉर्ट से संबंधित लीटकोड समस्याएं:
