内存管理中的堆更像是一个池。 有StackOverflow 上的讨论,我们不谈论这个不同的细节。你知道我们谈论算法和数据结构中的堆概念对我们来说就足够了。我们依然沿袭的风格算法简介。堆是用数组表示的完全二叉树。二叉树是树的一种,每个父节点最多有两个子节点,我们称之为左子树和右子树。
完美二叉树是层数为k时的二叉树,它有2层k
-1 个节点。像这样:我们可以认为完全二叉树是完美的二叉树泄漏或者不是缺少某些节点但必须从上到下、从左到右填充节点。
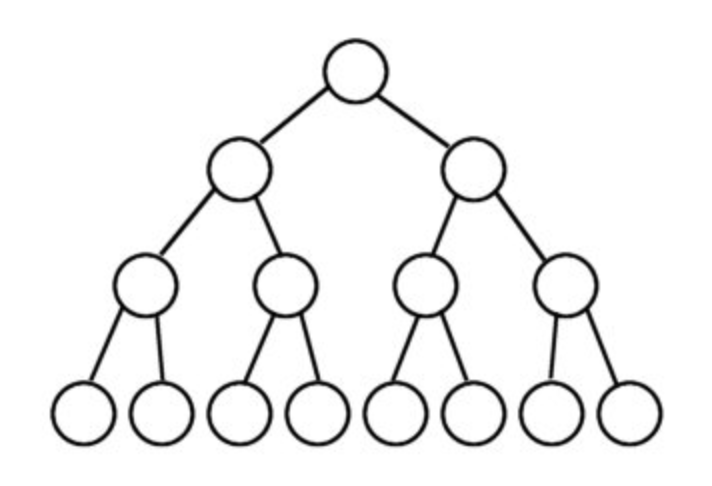
这意味着只能从右侧缺少一些节点。像这样:
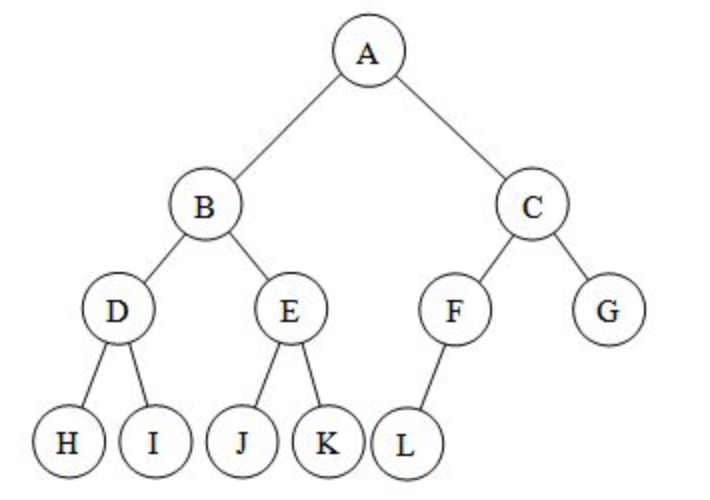
当我们用堆来存储这棵完整的二叉树时,我们可以将它保存为这样的数组:[A, B, C, D, E, F, G, H, I, J, K, L]。使用这种存储方式,我们会发现这棵树的根索引为1。
每个父节点的索引是子节点的索引除以2。左子节点的索引是其父节点的索引乘2,右子节点的索引是其父节点节点的索引乘以 2,然后加 1。
这样我们就得到了访问子节点和父节点的函数。

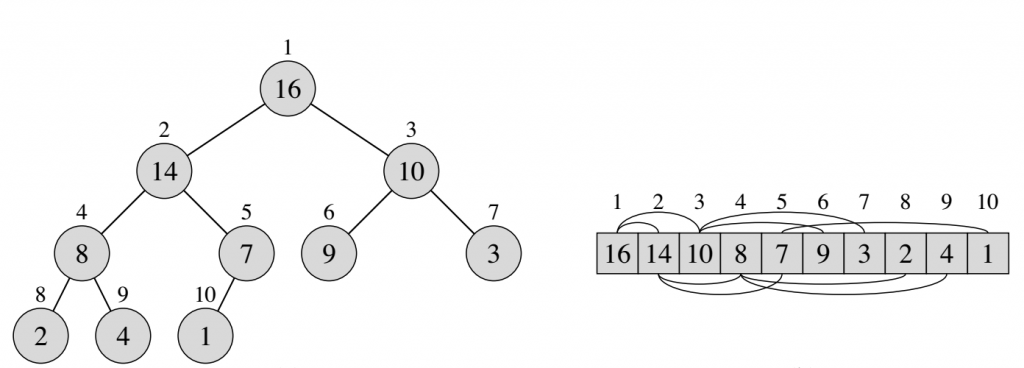
然后我们讨论一个数据结构,Max-Heap。它是一堆,每个父母都比它的孩子大。所以我们知道Max-Heap中root是最大的数。上图是一个Max-Heap及其对应的数组。
您可以轻松定义最小堆,我们现在不讨论它。
如果a的一个节点最大堆小于其子节点,违反了最大堆规则。如果我们知道它的子节点是有效的最大堆,我们可以通过最大堆化手术。步骤是我们比较这个节点和它的子节点的值,谁最大,如果不是父节点,我们将最大的子节点与父节点交换。然后我们检查子节点及其子节点。一步一步,我们可以确定操作后最大堆变得有效。
我们做了一个视频演示,4是错误节点。
这是代码。_A 是存储堆的数组,索引为 -1,因为在 Java 中数组的索引从 0 开始:

为了运行 Max-Heapify,我们编写了一个辅助函数交换:

那么我们如何从随机完全二叉树构建最大堆呢?假设我们有一个这样的堆:
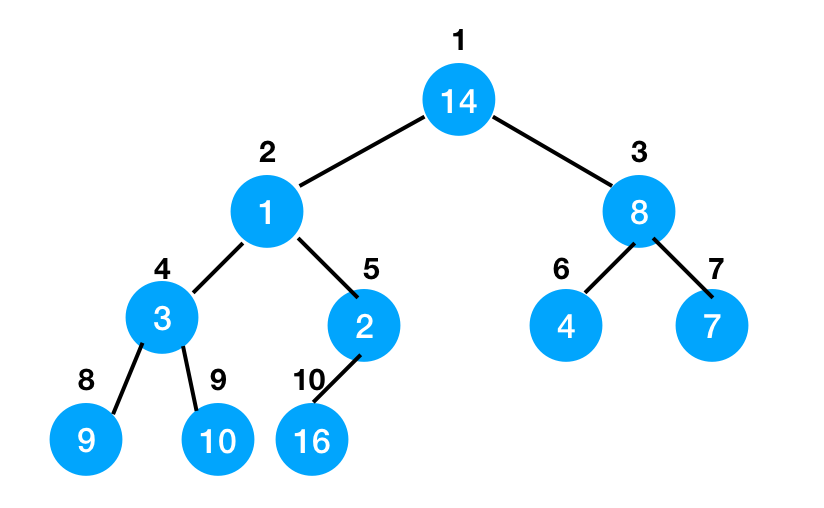
我们可以从堆的中间(第5个节点)开始,逐一回到根节点来执行max-heapify操作。完成后,我们就有了一个最大堆。这是一个演示视频:
代码如下:

当我们仔细观察时,我们会发现最大堆并不是一个有序的数据结构。每个父节点都比其子节点大,但左子节点可以大于也可以小于右子节点。我们无法仅通过以任何方式遍历二叉树来轻松获得有序数组。那么我们如何使用堆来对数字进行排序呢?
我们知道根永远是最大的。因此我们可以将根与最后一个节点交换,然后从堆中删除最后一个节点,并对根进行最大堆化。然后剩余的堆就成为有效的最大堆,我们可以一次又一次地这样做。我们总是把最大的数放在后面,这样我们就得到了一个有序数组。
我们可以从这个max-heap开始进行排序。

这是我们的演示视频:
代码如下:

并且 max-heap 可以支持一个操作提取最大,返回根,删除它,并收缩堆。我们可以用它来获取最大数或者k最大的数,而不用先排序。代码如下:

所以我们可以使用 max-heap 来对数字进行排序。或者我们可以用它来获取最大数或获取第 k 个最大的数,从而比排序花费更少的成本。
GitHub地址··https://github.com/tinyfool/leetcode/blob/master/src/CLRS/HeapSort.java
LeetCode 与堆和堆排序相关的问题:
