. DOI: 10.1038/s43588-024-00650-3")
Despite the vast amounts of human mobility data generated by smartphones, a lack of standardized formats, protocols, and privacy-protected open-source datasets hampers innovation across various sectors, including city planning, transportation design, public health, emergency response, and economic research. The absence of established benchmarks further complicates efforts to evaluate progress and share best practices.
Takahiro Yabe, assistant professor at the Center for Urban Science + Progress (CUSP) and Department of Technology Management and Innovation at NYU Tandon, recently collaborated with a team of researchers—Massimiliano Luca (Fondazione Bruno Kessler), Kota Tsubouchi (LY Corporation), Bruno Lepri (Fondazione Bruno Kessler), Marta C. Gonzalez (University of California, Berkeley), and Esteban Moro (Northeastern University)—to advocate for the necessity of open and standardized human mobility data.
Their opinion piece, published in Nature Computational Science, builds upon the recent release of the open-source, anonymized, large-scale human mobility dataset YJMob100K developed by several authors of the paper.
"The creation of the YJMob100K dataset and associated HuMob Challenge 2024 was motivated by our concern that similar human mobility datasets are exclusive to select researchers and industry organizations," said Yabe.
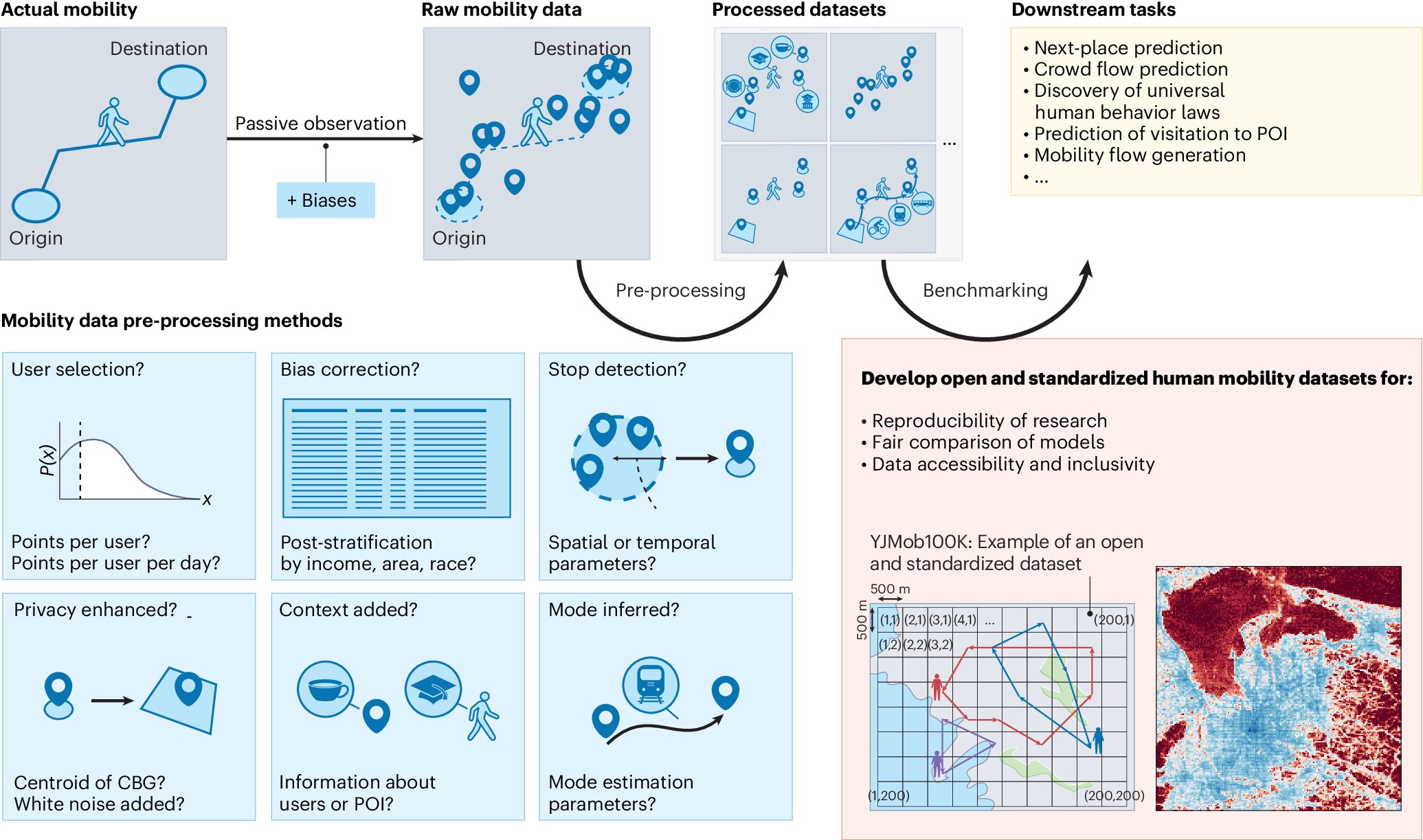
Unpacking the complexities of human mobility data pre-processing
Tracking a journey from origin to destination using mobile phone data is not straightforward. Data can vary significantly depending on the application employed, and datasets may not capture all transit modes. Inconsistencies in definitions, classifications, and data tags can introduce biases.
For example, defining what constitutes a "stop"—whether it's a pause of 5 minutes, 30 minutes, or an hour—can be somewhat subjective. "To detect a stop within a mobility trajectory, data scientists need to define arbitrary hyperparameters such as the minimum number of minutes spent at the stop and the maximum movement distance allowed from the stop centroid," noted the authors.
"With several hyperparameters needed for each pre-processing step, a slight change in the selection of these parameters could result in a very different processed human mobility dataset."
Pre-processing human mobility data is critical for protecting individual privacy. However, the methods used in this process are often kept confidential, creating a "black box" problem that raises concerns about data validity and accuracy.
To address these issues, companies evaluate datasets by comparing them with external sources such as census data. However, researchers aiming to introduce and evaluate new methods for predicting human mobility continue to face a significant hurdle: there is currently no standard open benchmark dataset.
Advancing human mobility research with the YJMob100K dataset
The authors propose two strategies for approaching this challenge: creating synthetic, privacy-preserving human mobility datasets using machine learning models, or anonymizing a large-scale mobility dataset through collaboration with a private company.
The latter strategy was employed for YJMob100K, which was developed through a collaboration involving Takahiro Yabe from NYU Tandon, Yoshihide Sekimoto and Kaoru Sezaki from the University of Tokyo, Esteban Moro and Alex Pentland from MIT, along with Kota Tsubouchi and Toru Shimizu from the private Japanese internet company LY Corporation.
The YJMob100K dataset was anonymized by converting location pings into 500x500 meter grid cells and aggregating timestamps into 30-minute intervals while masking the actual dates. Individuals who contributed data signed a consent form outlining the frequency and accuracy of location data collection as well as its intended use. All data processing and analysis were conducted on servers managed by the company.
To promote the dataset, the authors initiated the Human Mobility Prediction Challenge (HuMob Challenge) in 2023, which is currently underway for its second year. Selected entries will be showcased at the ACM SIGSPATIAL conference, taking place in Atlanta from October 29 to November 1, 2024.
"Inspired by advancements in natural language processing models like transformers, many submissions in the 2023 edition used AI and machine learning approaches," said Yabe. "Eight of the top 10 submissions used deep learning techniques. With over 85 teams and 200 participants from 22 countries, the overwhelming response motivated us to continue into 2024. This year's challenge is more advanced, targeting predictions for cities that lack data."
The authors have identified several key challenges they aim to address in their future work. First, they aim to establish criteria for creating "fit-for-purpose" benchmarking datasets to achieve consensus within the research community. This involves defining clear metrics for data specification and establishing industry standards for pre-processing.
Second, recognizing that different tasks require different types of data, they propose creating a collection of "fit-for-purpose" datasets, each tailored to specific research domains, communities, and socio-spatial-temporal contexts. This necessitates a bottom-up approach led by relevant research communities to ensure the datasets are well-aligned with their intended uses.
More information: Takahiro Yabe et al, Enhancing human mobility research with open and standardized datasets, Nature Computational Science (2024). DOI: 10.1038/s43588-024-00650-3
Citation: Researchers advocate for open and standardized human mobility data (2024, August 15) retrieved 15 August 2024 from https://techxplore.com/news/2024-08-advocate-standardized-human-mobility.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no part may be reproduced without the written permission. The content is provided for information purposes only.