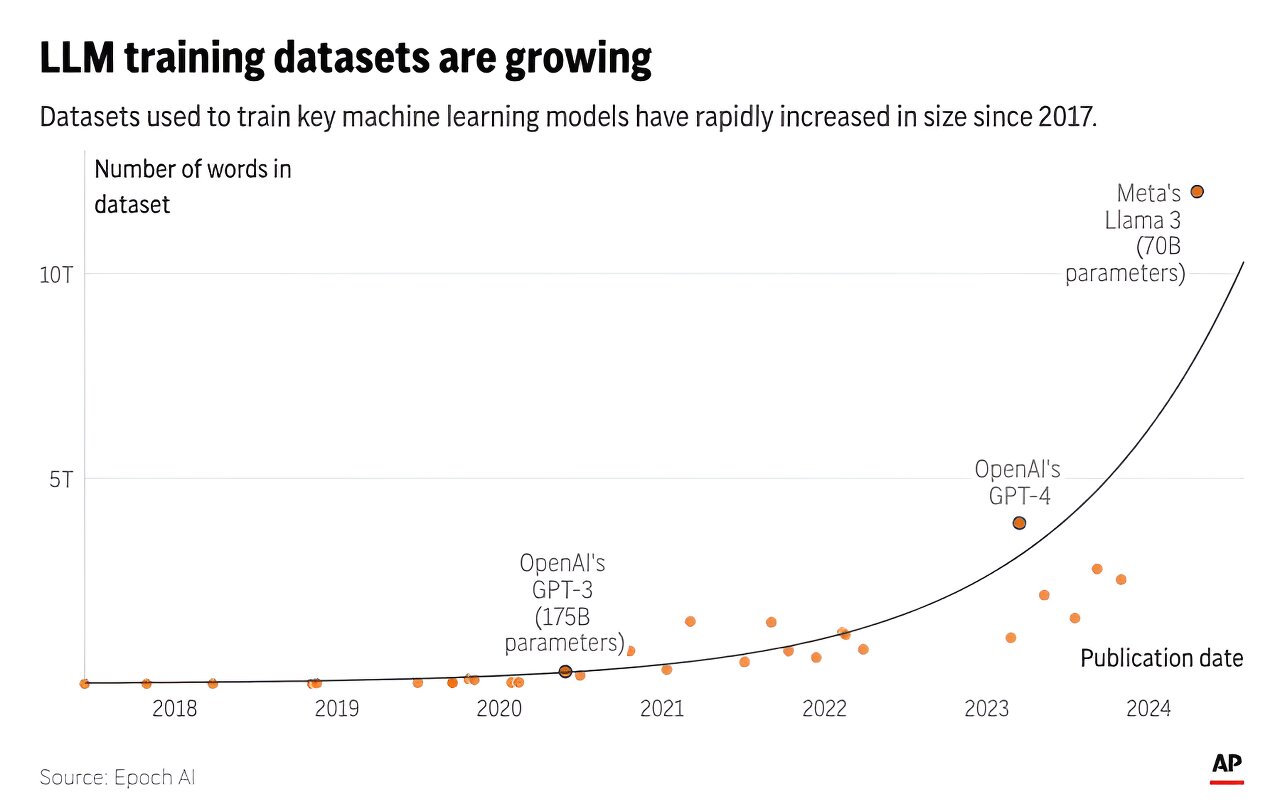

Artificial intelligence systems like ChatGPT could soon run out of what keeps making them smarter—the tens of trillions of words people have written and shared online.
A new study released Thursday by research group Epoch AI projects that tech companies will exhaust the supply of publicly available training data for AI language models by roughly the turn of the decade—sometime between 2026 and 2032.
Comparing it to a "literal gold rush" that depletes finite natural resources, Tamay Besiroglu, an author of the study, said the AI field might face challenges in maintaining its current pace of progress once it drains the reserves of human-generated writing.
In the short term, tech companies like ChatGPT-maker OpenAI and Google are racing to secure and sometimes pay for high-quality data sources to train their AI large language models—for instance, by signing deals to tap into the steady flow of sentences coming out of Reddit forums and news media outlets.
In the longer term, there won't be enough new blogs, news articles and social media commentary to sustain the current trajectory of AI development, putting pressure on companies to tap into sensitive data now considered private—such as emails or text messages—or relying on less-reliable "synthetic data" spit out by the chatbots themselves.
"There is a serious bottleneck here," Besiroglu said. "If you start hitting those constraints about how much data you have, then you can't really scale up your models efficiently anymore. And scaling up models has been probably the most important way of expanding their capabilities and improving the quality of their output."
The researchers first made their projections two years ago—shortly before ChatGPT's debut—in a working paper that forecast a more imminent 2026 cutoff of high-quality text data. Much has changed since then, including new techniques that enabled AI researchers to make better use of the data they already have and sometimes "overtrain" on the same sources multiple times.
But there are limits, and after further research, Epoch now foresees running out of public text data sometime in the next two to eight years.
The team's latest study is peer-reviewed and due to be presented at this summer's International Conference on Machine Learning in Vienna, Austria. Epoch is a nonprofit institute hosted by San Francisco-based Rethink Priorities and funded by proponents of effective altruism—a philanthropic movement that has poured money into mitigating AI's worst-case risks.
Besiroglu said AI researchers realized more than a decade ago that aggressively expanding two key ingredients—computing power and vast stores of internet data—could significantly improve the performance of AI systems.
More information: Pablo Villalobos et al, Will we run out of data? Limits of LLM scaling based on human-generated data, arXiv (2022). DOI: 10.48550/arxiv.2211.04325
Journal information: arXiv
© 2024 The Associated Press. All rights reserved. This material may not be published, broadcast, rewritten or redistributed without permission.
Citation: AI 'gold rush' for chatbot training data could run out of human-written text (2024, June 6) retrieved 6 June 2024 from https://techxplore.com/news/2024-06-ai-gold-chatbot-human-written.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no part may be reproduced without the written permission. The content is provided for information purposes only.