Lameness Disclaimer: All this is written to the best of my knowledge. Corrections, additions etc. are certainly welcome.
You can download the make based project, that contains the demo code disucssed.
Optimize this
Imagine you feel the need to optimize this piece of code
- (void) operateAnnihilateNaive { int n; int i; id p; n = [_array count]; for( i = 0; i < n; i++) { p = [_array objectAtIndex:i]; [p operate]; [p annihilate]; } }
as much as possible. What is known about any
pis, that it is based on NSObject (by virtue of existing in an NSArray) and that it implements the methods
operateand
annihilate(else our code is faulty).
Sharking here for a minute
Running a demo through Shark reveals, that most of the time is spent in
objc_msgSend.
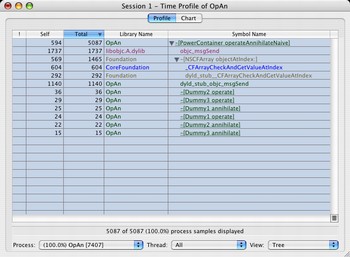
This isn't quite a surprise, because in the demo code the classes of the objects in the array have implementations like this:
@implementation Dummy1 - (void) operate { } - (void) annihilate { } @end
which compile to one little return instruction (with the new gcc compilers and optimization enabled).
-[Dummy1 operate]: 000029f0 blr 000029f4 nop 000029f8 nop 000029fc nop
|
We can see that -[NSArray objectAtIndex:] calls a CoreFoundation function to do the actual work, which is vectored through a dyld_stub... By using CoreFoundation directly, we can gain a surprising bit of performance:
- (void) operateAnnihilateNaiveCore { int n; int i; id p; n = [_array count]; for( i = 0; i < n; i++) { p = CFArrayGetValueAtIndex( (CFArrayRef) _array, (CFIndex) i); [p operate]; [p annihilate]; } } As a next step let's use function pointers to access CFArrayGetValueAtIndex as shown in a previous article.- (void) operateAnnihilate { void *(*f)(); int n; int i; id p; f = (void *) CFArrayGetValueAtIndex; n = [_array count]; for( i = 0; i < n; i++) { p = (*f)( _array, i); [p operate]; [p annihilate]; } } and then also use a function pointer to access objc_msgSend- (void) operateAnnihilateFast { SEL operateSel; SEL annihilateSel; void *(*f)(); int n; int i; id p; id (*objc_call)( id, SEL, ...); objc_call = objc_msgSend; f = (void *) CFArrayGetValueAtIndex; n = [_array count]; for( i = 0; i < n; i++) { p = (*f)( _array, i); (*objc_call)( p, @selector( operate)); (*objc_call)( p, @selector( annihilate)); } } |
|

The result is :
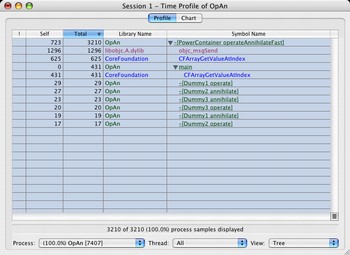
Still the majority of the time is spent in objc_msgSend, but it is already way faster. So far this was nothing new.
| operateAnnhilateNaive | 10071 ms |
|---|---|
| operateAnnhilateNaiveCore | 7313 ms |
| operateAnnhilate | 6979 ms |
| operateAnnhilateFast | 6255 ms |
One Step Further
If we look at regular IMP caching, we have one class and one selector resulting in one method address. That address we cache in a local variable. If we have multiple classes and/or multiple selectors, this fails.
The Objective-C runtime caches method addresses in the class structure. It has one cache for all methods of a class. As shown in article The faster objc_msgSend, access to the class cache is pretty quick in objc_msgSend, alas not quite as quick as possible.
|
The idea in the next function is to use our own little IMP cache and forego execution of objc_msgSend completely. We have a known number
of selectors (2, annihilate and operate) and a unknown number of objects with an equally unknown number of classes implementing these two
selectors. So let's make two little caches that are indexed by class to store and retrieve method addresses. In the demo code, we know there are
relatively few classes. So the cache size will be minuscule (8 entries).
To get the address of the method, we could be using methodForSelector:, but that would still use objc_msgSend, and would slow down the worst case considerably. The worst case being constant cache misses. By the same reasoning we don't want to use the method -class to get to the class structure. Getting the isa pointer of an NSObject base instance is relatively easy, if we use the useful @defs construct: static inline Class _isa( NSObject *obj) { return( ((struct { @defs( NSObject) } *) obj)->isa); } |
|
As a substitute for
methodForSelector:the Objective-C runtime function
class_lookupMethodis used. It uses the same mechanics as
objc_msgSendto determine the address, but returns it, instead of jumping to it. So the worst case, which would be continous cache misses and calls to
class_lookupMethodshould not turn out to slow things down to the point, where this exercise would be pointless.
- (void) operateAnnihilateFastest { IMP lastOpIMP[ 8]; IMP lastAnIMP[ 8]; Class lastIsa[ 8]; Class thisIsa; unsigned int index; void *(*f)(); int n; int i; id p; f = (void *) CFArrayGetValueAtIndex; n = [_array count]; memset( lastIsa, 0, sizeof( lastIsa)); for( i = 0; i < n; i++) { p = (*f)( _array, i); thisIsa = _isa( p); index = ((unsigned long) thisIsa >> 4) & 7; if( lastIsa[ index] != thisIsa) { if( ! (lastOpIMP[ index] = class_lookupMethod( thisIsa, @selector( operate)))) [NSException raise:NSGenericException format:@"No operate method on class %s", ((struct objc_class *) thisIsa)->name]; if( ! (lastAnIMP[ index] = class_lookupMethod( thisIsa, @selector( annihilate)))) [NSException raise:NSGenericException format:@"No annihilate method on class %s", ((struct objc_class *) thisIsa)->name]; lastIsa[ index] = thisIsa; } (*lastOpIMP[ index])( p, @selector( operate)); (*lastAnIMP[ index])( p, @selector( annihilate)); } }
And there you have it.
| operateAnnhilateFastest | 5102 ms |
|---|---|
| operateAnnhilateFastestWorstCase | 8895 ms |
The final profile has a touch of beauty to it.
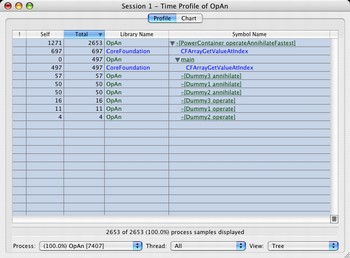
So operateAnnihilateFastest runs twice as fast as operateAnnihilateNaive. In hardware this would be like the difference between 400 Mhz and 800 Mhz. :) And half of the time is now spent in CFArrayGetValueAtIndex. See Optimizing Foundation Classes how you could tackle this. If you were to replace the NSArray with a C array, you might reach 1200 Mhz :)
MulleAutoreleasePool, a practical application
If you like download this XCode 1.5 project, which contains the source for
MulleAutoreleasePooland a small benchmarking program. This code is used in a real life project, so I'd assume it to be quite useable.
The local IMP cache shows its strength when the container has a large number of objects and the implementations of the selectors are rather quick, in terms of execution speed. A candidate for a sample implementation is a
NSAutoreleasePoolreplacement, because autorelease pools can contain thousands of objects at one time, and the
releasemethods called are typically fast.
If you look at mulleAutoreleasePoolReleaseAll you will see similiar code employed as in operateAnnihilateFastest with only a larger cache size, to reduce the likelyhood of cache misses.
It would break the scope of this article to go over the implementation in detail. So I want you to just take in some benchmark results. The objects in the pool are a random collection of Foundation basic types, like NSString, NSNumber, NSData and so on. The types that are usually most numerously instantiated.
| Operation | NSAutoreleasePool | MulleAutoreleasePool |
|---|---|---|
| Adding 5000 Objects to a pool then releasing that pool. This is done 2000 times. | 1417 ms | 835 ms |
| Adding 5000 Objects 2000 times to a pool | 1198 ms | 500 ms |
| Releasing that pool | 1482 ms | 504 ms |
It's not my fault, that my implementation appears to be much more efficient in memory usage and organization. Given the closed source nature of Foundation, it is unclear how much of the gain can be attributed to IMP Caching Deluxe.
If you want to discuss this articles, please do so in this thread on the newly opened Mulle kybernetiK Optimization Forum
1 I think this could be done a whole lot better, but that's for another article.