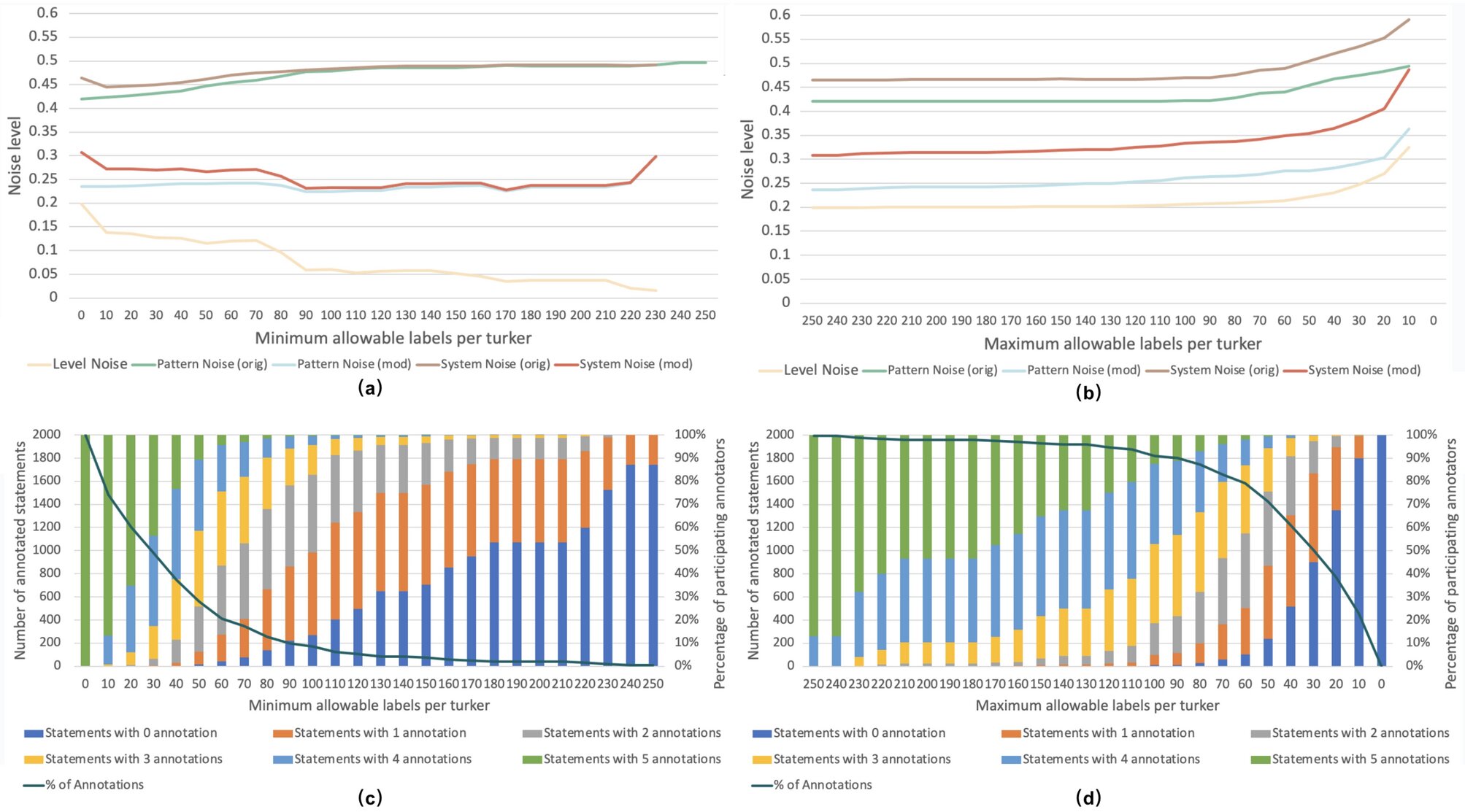
 and maximum (b) allowable labels for each turker (we omit the residual in these two figures as, similar to what was observed earlier for TG-CSR, it was nearly coincidental with the level noise curve). We also report the statistics of statements categorized by the number of annotation labels under different cutoff methods used for screening participating annotators in (c) and (d). Credit: Scientific Reports (2024). DOI: 10.1038/s41598-024-58937-4")
多くの人はバイアスの概念を直感的なレベルで理解しています。社会においても、人工知能システムにおいても、人種的およびジェンダー的な偏見十分に文書化されています。
もし社会が何らかの形で偏見を取り除くことができれば、すべての問題は解決するのでしょうか?故ノーベル賞受賞者ダニエル・カーネマン行動経済学の分野で重要な人物であった彼は、著書の中でこう主張した。最後の本その偏見はコインの片面にすぎません。判断の誤りは、バイアスとノイズという 2 つの原因に起因する可能性があります。
バイアスとノイズは両方とも次のような分野で重要な役割を果たします。法、薬そして財務予測、 どこ人間の判断が中心。コンピューターおよび情報科学者としての私たちの仕事において、私の同僚や私そのノイズも発見しましたAIで役割を果たす。統計的ノイズ
この文脈でのノイズとは、同じ問題や状況に対して人々がどのように判断するかが異なることを意味します。
騒音の問題は、見た目よりもさらに広範囲に広がっています。あ独創的な作品は大恐慌時代まで遡り、同様の事件に対して裁判官によって判決が異なることが判明した。
心配なことに、裁判での量刑は次のような事柄によって左右される可能性があります。温度そして、地元のサッカーチームが勝ちました。このような要因は、少なくとも部分的には、司法制度が偏っているだけでなく、時には恣意的であるという認識に寄与しています。
その他の例: 保険査定人は、同様の請求に対して異なる見積もりを提示する可能性があります。彼らの判断にノイズがある。ワインの試飲から地元の美人コンテスト、大学入学に至るまで、あらゆる種類のコンテストで騒音が発生する可能性があります。
データ内のノイズ
表面的には、ノイズが AI システムのパフォーマンスに影響を与える可能性は低いように思えます。結局のところ、機械は天候やサッカーチームの影響を受けないのに、なぜ状況によって異なる判断を下すのでしょうか?一方で、研究者は次のことを知っています。偏見はAIに影響を与える、それはそうだからですデータに反映されるAIが訓練されているもの。
ChatGPT のような新しい AI モデルのゴールドスタンダードは、人間のパフォーマンスなどの一般的な知能の問題について常識。ChatGPT とそのピアは人間のラベルに対して測定常識的なデータセット。
簡単に言えば、研究者や開発者は機械に常識的な質問をし、それを人間の答えと比較することができます。「紙のテーブルの上に重い石を置くと、崩れますか? はい、それともいいえです。」テストによると、両者の間に高い一致がある場合 (最良の場合は完全に一致)、マシンは人間レベルの常識に近づいています。
では、どこからノイズが入ってくるのでしょうか?上記の常識的な質問は単純に見え、ほとんどの人間がその答えに同意する可能性が高いですが、「次の文はもっともらしいですか、それともありえませんか? 私の犬はバレーボールをしています。」など、より不一致または不確実性がある質問もたくさんあります。つまり、ノイズが発生する可能性があります。興味深い常識的な質問にノイズが含まれていても不思議ではありません。
しかし問題は、ほとんどの AI テストでは実験におけるこのノイズが考慮されていないことです。直観的には、互いに一致する傾向にある人間の回答を生成する質問は、回答が異なる場合、つまりノイズがある場合よりも重み付けが高くなります。研究者たちは、そのような状況でAIの答えを比較検討するかどうか、あるいはどのように比較検討するべきかまだ分かっていないが、最初のステップは問題が存在することを認識することだ。
機械内の騒音を追跡する
理論はさておき、上記のすべてが仮説なのか、それとも実際の常識のテストでノイズが存在するのかという疑問は依然として残ります。ノイズの存在を証明または反証する最良の方法は、既存のテストを実施し、回答を削除し、複数の人に独立してラベルを付けてもらい、回答を提供してもらうことです。人間間の不一致を測定することで、研究者はテストにどれだけのノイズが含まれているかを知ることができます。
この不一致を測定する背後にある詳細は複雑であり、重要な統計と数学が関係します。それに、常識とはどのように定義されるべきなのか、誰が言えるのでしょうか?人間の裁判官が質問を熟考するのに十分な動機を持っているとどのようにしてわかりますか?これらの問題は、優れた実験計画と統計の交差点にあります。堅牢性が鍵です。人間のラベラーによる 1 つの結果、テスト、またはセットでは、誰も納得する可能性は低いです。実際的な問題として、人間の労働力は高価です。おそらくこの理由から、AI テストにおけるノイズの可能性についての研究は行われていません。
このギャップに対処するために、同僚と私はこのような研究を計画し、私たちの調査結果を発表しましたで科学レポート、常識の範囲内であってもノイズは避けられないことを示しています。判断が導き出される環境が重要になる可能性があるため、私たちは 2 種類の研究を行いました。研究の 1 つは、以下の国の有給労働者を対象としたものです。アマゾン・メカニカル・ターク一方、もう 1 つの研究では、南カリフォルニア大学とレンセラー工科大学の 2 つの研究室で小規模なラベル付け実験が行われました。
前者は、トレーニングと評価のためにリリースされる前に実際にラベル付けされる AI テストの数を反映する、より現実的なオンライン設定と考えることができます。後者はより極端で、高品質は保証されますが、規模ははるかに小さくなります。私たちが答えようとしたのは、ノイズがどれほど避けられないのか、そしてそれは単に品質管理の問題なのかということでした。
結果は厳粛なものでした。どちらの設定でも、高い、あるいは普遍的な同意を引き出すことが期待される常識的な質問であっても、無視できない程度のノイズが存在することがわかりました。ノイズが十分に高かったため、システムのパフォーマンスの 4% ~ 10% がノイズに起因している可能性があると推測されました。
これが何を意味するかを強調するために、私がテストで 85% を達成した AI システムを構築し、あなたが 91% を達成した AI システムを構築したとします。あなたのシステムは私のシステムよりもはるかに優れているようです。しかし、回答を採点するために使用された人間によるラベルにノイズがある場合、6% の改善が大きな意味を持つかどうかはもはやわかりません。私たちが知っている限りでは、本当の改善は存在しない可能性があります。
ChatGPT を強化するような大規模な言語モデルが比較される AI リーダーボードでは、ライバル システム間のパフォーマンスの差ははるかに小さく、通常は 1% 未満です。この論文で示したように、通常の統計は、ノイズの影響と真のパフォーマンス向上の影響を区別するのに実際には役に立ちません。
騒音監査
今後の道は何でしょうか?カーネマンの著書に戻ると、彼は騒音を定量化し、最終的には可能な限り軽減するための「騒音監査」の概念を提案しました。少なくとも、AI 研究者はノイズがどのような影響を与える可能性があるかを推定する必要があります。
AI システムのバイアスを監査することはある程度一般的であるため、ノイズ監査の概念も自然に続くべきだと考えています。私たちは、この研究や他の同様の研究が採用につながることを願っています。
詳細情報:Mayank Kejriwal 他、機械の常識推論のための人間によるラベル付けされたベンチマークのノイズ監査、科学レポート(2024年)。DOI: 10.1038/s41598-024-58937-4
この記事はから転載されています会話クリエイティブ・コモンズ・ライセンスに基づいて。読んでください元の記事。![]()
引用:機械内の「ノイズ」: 人間の判断の違いが AI の問題を引き起こす (2024 年 5 月 15 日)2024 年 5 月 15 日に取得https://techxplore.com/news/2024-05-noise-machine-human-differences-judgment.html より
この文書は著作権の対象です。個人的な研究や研究を目的とした公正な取引を除き、書面による許可なく一部を複製することができます。コンテンツは情報提供のみを目的として提供されています。