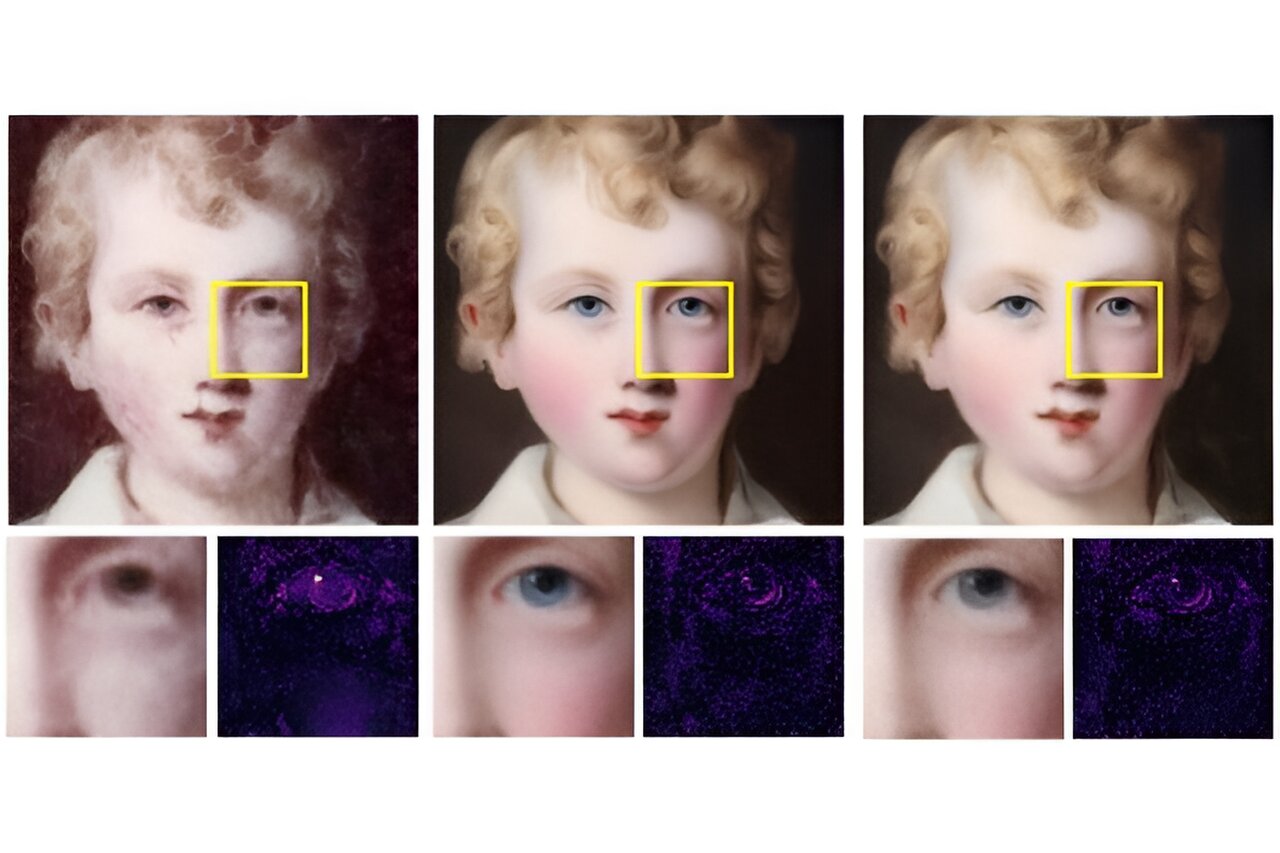
 deep learning models in PnP-ADMM for the phase retrieval problem. The mismatched model is trained on pathology images instead of faces (matched). The proposed method applies domain adaptation to the mismatched model to restore a high-quality image, comparable in quality to the results achieved using the matched model, with fewer than 1% of the number of images required for training. Credit: Kamilov lab")
गहन शिक्षण मॉडल, जैसे कि बीमारी या असामान्यताओं का पता लगाने में मदद के लिए मेडिकल इमेजिंग में उपयोग किए जाने वाले मॉडल को बहुत सारे डेटा के साथ प्रशिक्षित किया जाना चाहिए।हालाँकि, अक्सर इन मॉडलों को प्रशिक्षित करने के लिए पर्याप्त डेटा उपलब्ध नहीं होता है, या डेटा बहुत विविध होता है।
सेंट लुइस में वाशिंगटन विश्वविद्यालय के मैककेल्वे स्कूल ऑफ इंजीनियरिंग में कंप्यूटर विज्ञान और इंजीनियरिंग और इलेक्ट्रिकल और सिस्टम इंजीनियरिंग के एसोसिएट प्रोफेसर उलुगबेक कामिलोव ने अपने समूह के डॉक्टरेट छात्रों शिरीन शुश्तारी, जियामिंग लियू और एडवर्ड चांडलर के साथ मिलकर एक विकसित किया है।इस सामान्य समस्या से निजात पाने का तरीकाछवि पुनर्निर्माण.
टीम प्रस्तुत करेगीपरिणामइस महीने मशीन लर्निंग पर अंतर्राष्ट्रीय सम्मेलन में शोध का (आईसीएमएल 2024) वियना, ऑस्ट्रिया में।
उदाहरण के लिए, गहन शिक्षण मॉडल को प्रशिक्षित करने के लिए उपयोग किया जाने वाला एमआरआई डेटा विभिन्न विक्रेताओं, अस्पतालों, मशीनों, रोगियों या चित्रित शरीर के अंगों से आ सकता है।एक प्रकार के डेटा पर प्रशिक्षित मॉडल अन्य डेटा पर लागू होने पर त्रुटियां पेश कर सकता है।उन त्रुटियों से बचने के लिए, टीम ने व्यापक रूप से उपयोग किए जाने वाले गहन शिक्षण दृष्टिकोण को अपनाया, जिसे प्लग-एंड-प्ले प्रायर्स के रूप में जाना जाता है, उस डेटा में बदलाव के लिए जिम्मेदार था जिसके साथ मॉडल को प्रशिक्षित किया गया था और मॉडल को डेटा के नए आने वाले सेट के लिए अनुकूलित किया गया था।
शौश्तारी ने कहा, "हमारी पद्धति के साथ, इससे कोई फर्क नहीं पड़ता कि आपके पास बहुत अधिक प्रशिक्षण डेटा नहीं है।""हमारी पद्धति अनुकूलन को सक्षम बनाती हैगहन शिक्षण मॉडलप्रशिक्षण डेटा के एक छोटे से सेट का उपयोग करते हुए, इससे कोई फर्क नहीं पड़ता कि चित्र किस अस्पताल, किस मशीन या शरीर के किस हिस्से से आए हैं।
शौश्तरी ने कहा, "डोमेन अनुकूलन रणनीति के बारे में महत्वपूर्ण बात यह है कि हम डेटा के सीमित सेट के कारण इमेजिंग में होने वाली त्रुटियों को कम कर सकते हैं।""इससे हमें उन समस्याओं पर गहन शिक्षण लागू करने में मदद मिल सकती है जिन्हें पहले डेटा आवश्यकताओं के कारण असंभव माना जाता था।"
इस पद्धति का एक प्रस्तावित उपयोग एमआरआई से डेटा प्राप्त करना होगा, जिसके लिए रोगियों को लंबे समय तक लेटे रहने की आवश्यकता होती है।रोगी की कोई भी हरकत त्रुटियों का कारण बनती है।
शुश्तारी ने कहा, "हमने कम समय में एमआरआई से डेटा प्राप्त करने पर विचार किया है।""जबकि छोटे स्कैन से आम तौर पर कम गुणवत्ता वाली छवियां प्राप्त होती हैं, हमारी विधि का उपयोग कम्प्यूटेशनल रूप से बढ़ाने के लिए किया जा सकता हैछवि के गुणवत्ताजैसे कि मरीज काफी देर तक मशीन में था।हमारे नए दृष्टिकोण में मुख्य नवाचार यह है कि मौजूदा एमआरआई मॉडल को नए डेटा में अनुकूलित करने के लिए केवल दसियों छवियों की आवश्यकता होती है।"
यह विधि रेडियोलॉजी से परे भी लागू है, और टीम वैज्ञानिक इमेजिंग, सूक्ष्म इमेजिंग और अन्य अनुप्रयोगों के लिए विधि को अपनाने के लिए अन्य सहयोगियों के साथ सहयोग कर रही है जिसमें डेटा को एक छवि के रूप में दर्शाया जा सकता है।
अधिक जानकारी:शौश्तारी एस, लियू जे, चांडलर ईपी, आसिफ एमएस, कामिलोव यूएस।गैर-उत्तल अभिसरण विश्लेषण के साथ पीएनपी-एडीएमएम में पूर्व बेमेल और अनुकूलन।मशीन लर्निंग पर अंतर्राष्ट्रीय सम्मेलन, 21-27 जुलाई, 2024।icml.cc/virtual/2024/poster/34765
स्रोत कोड GitHub पर उपलब्ध है:github.com/wustl-cig/MMPnPADMM
उद्धरण:गहन शिक्षण मॉडल को सीमित डेटा के साथ प्रशिक्षित किया जा सकता है: नई विधि कम्प्यूटेशनल इमेजिंग में त्रुटियों को कम कर सकती है (2024, 26 जुलाई)26 जुलाई 2024 को पुनः प्राप्तhttps://techxplore.com/news/2024-07-dep-limited-method-errors-images.html से
यह दस्तावेज कॉपीराइट के अधीन है।निजी अध्ययन या अनुसंधान के उद्देश्य से किसी भी निष्पक्ष व्यवहार के अलावा, नहींलिखित अनुमति के बिना भाग को पुन: प्रस्तुत किया जा सकता है।सामग्री केवल सूचना के प्रयोजनों के लिए प्रदान की गई है।