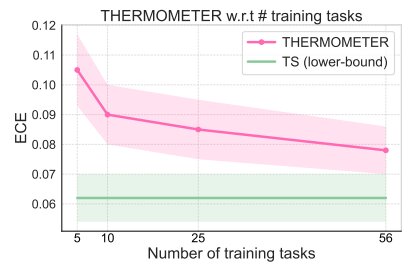
 improves as the number of training datasets increase. The shaded region represents two standard error. Credit: arXiv (2024). DOI: 10.48550/arxiv.2403.08819")
La gente utiliza grandes modelos de lenguaje para una gran variedad de tareas, desde traducir un artículo hasta identificar un fraude financiero.Sin embargo, a pesar de las increíbles capacidades y versatilidad de estos modelos, en ocasiones generan respuestas inexactas.
Además de ese problema, los modelos pueden tener exceso de confianza en las respuestas incorrectas o falta de confianza en las correctas, lo que dificulta que un usuario sepa cuándo se puede confiar en un modelo.
Los investigadores suelen calibrar unmodelo de aprendizaje automáticopara garantizar que su nivel de confianza se alinee con su precisión.Un modelo bien calibrado debería tener menos confianza ante una predicción incorrecta y viceversa.Pero porquegrandes modelos de lenguaje(LLM) se pueden aplicar a una colección aparentemente interminable de diversas tareas, los métodos de calibración tradicionales son ineficaces.
Ahora, investigadores del MIT y del MIT-IBM Watson AI Lab han introducido un método de calibración adaptado a grandes modelos de lenguaje.Su método, llamado Termómetro, implica construir un modelo auxiliar más pequeño que se ejecuta sobre un modelo de lenguaje grande para calibrarlo.
El termómetro es más eficiente que otros enfoques, ya que requiere menos cálculos que consumen menos energía, al tiempo que preserva la precisión del modelo y le permite producir respuestas mejor calibradas en tareas que nunca antes se habían visto.
Al permitir la calibración eficiente de un LLM para una variedad de tareas, Thermometer podría ayudar a los usuarios a identificar situaciones en las que un modelo confía demasiado en predicciones falsas, lo que en última instancia les impide implementar ese modelo en una situación en la que pueda fallar.
"Con Thermometer, queremos brindarle al usuario una señal clara que le diga si la respuesta de un modelo es precisa o inexacta, de una manera que refleje la incertidumbre del modelo, para que sepa si ese modelo es confiable", dice Maohao Shen, unelectrotecniae estudiante de posgrado en ciencias de la computación (EECS) y autor principal de un artículo sobre termómetro.
A Shen se une en el artículo Gregory Wornell, profesor de ingeniería de Sumitomo que dirige el Laboratorio de Señales, Información y Algoritmos en el Laboratorio de Investigación de Electrónica, y es miembro del Laboratorio de IA Watson del MIT-IBM;la autora principal Soumya Ghosh, miembro del personal de investigación del Laboratorio de IA Watson del MIT-IBM;así como otros en el MIT y el MIT-IBM Watson AI Lab.
La investigación se presentó recientemente en la Conferencia Internacional sobre Aprendizaje Automático (ICML 2024) celebrada en Viena, Austria, del 21 al 27 de julio. Esdisponibleen elarXivservidor de preimpresión.
Calibración universal
Dado que los modelos tradicionales de aprendizaje automático suelen estar diseñados para realizar una única tarea, calibrarlos suele implicar un método específico para la tarea.Por otro lado, dado que los LLM tienen la flexibilidad de realizar muchas tareas, utilizar un método tradicional para calibrar ese modelo para una tarea podría perjudicar su desempeño en otra tarea.
Calibrar un LLM a menudo implica tomar muestras del modelo varias veces para obtener diferentes predicciones y luego agregar estas predicciones para obtener una confianza mejor calibrada.Sin embargo, debido a que estos modelos tienen miles de millones de parámetros, los costos computacionales de tales enfoques se acumulan rápidamente.
"En cierto sentido, los modelos de lenguaje grandes son universales porque pueden manejar diversas tareas. Por lo tanto, necesitamos un método de calibración universal que también pueda manejar muchas tareas diferentes", dice Shen.
Con Thermometer, los investigadores desarrollaron una técnica versátil que aprovecha un método de calibración clásico llamado escalado de temperatura para calibrar eficientemente un LLM para una nueva tarea.
En este contexto, una "temperatura" es un parámetro de escala que se utiliza para ajustar la confianza de un modelo para que esté alineado con su precisión de predicción.Tradicionalmente, se determina la temperatura adecuada utilizando un conjunto de datos de validación etiquetados de ejemplos de tareas específicas.
Dado que los LLM a menudo se aplican a nuevas tareas, adquirir conjuntos de datos etiquetados puede ser casi imposible.Por ejemplo, un usuario que desea implementar un LLM para responder las preguntas de los clientes sobre un nuevo producto probablemente no tenga un conjunto de datos que contenga dichas preguntas y respuestas.
En lugar de utilizar un conjunto de datos etiquetados, los investigadores entrenan un modelo auxiliar que se ejecuta sobre un LLM para predecir automáticamente la temperatura necesaria para calibrarlo para esta nueva tarea.
Utilizan conjuntos de datos etiquetados de algunas tareas representativas para entrenar el modelo de termómetro, pero luego, una vez entrenado, pueden generalizarse a nuevas tareas en una categoría similar sin la necesidad de datos etiquetados adicionales.
Un modelo de termómetro entrenado en una colección de conjuntos de datos de preguntas de opción múltiple, quizás incluyendo uno con preguntas de álgebra y otro con preguntas médicas, podría usarse para calibrar un LLM que responda preguntas sobre geometría o biología, por ejemplo.
"El objetivo al que se aspira es que funcione en cualquier tarea, pero aún no hemos llegado a ese punto", dice Ghosh.
El modelo de termómetro solo necesita acceder a una pequeña parte del funcionamiento interno del LLM para predecir la temperatura correcta que calibrará su predicción para puntos de datos de una tarea específica.
Un enfoque eficiente
Es importante destacar que la técnica no requiere múltiples ejecuciones de entrenamiento y solo ralentiza ligeramente el LLM.Además, dado que el escalado de temperatura no altera las predicciones de un modelo, Thermometer conserva su precisión.
Cuando compararon Thermometer con varias líneas de base en múltiples tareas, produjo consistentemente medidas de incertidumbre mejor calibradas y requirieron muchos menos cálculos.
"Siempre que entrenemos un modelo de termómetro en una cantidad suficientemente grande de tareas, debería poder generalizarse bien en cualquier tarea nueva, al igual que un modelo de lenguaje grande, también es un modelo universal", añade Shen.
Los investigadores también descubrieron que si entrenan un modelo de termómetro para un LLM más pequeño, se puede aplicar directamente para calibrar un LLM más grande dentro de la misma familia.
En el futuro, quieren adaptar Thermometer para tareas de generación de texto más complejas y aplicar la técnica a LLM aún más grandes.Los investigadores también esperan cuantificar la diversidad y la cantidad de conjuntos de datos etiquetados que se necesitarían para entrenar un modelo de termómetro para que pueda generalizarse a una nueva tarea.
Más información:Maohao Shen et al, Termómetro: hacia la calibración universal para modelos de lenguaje grandes,arXiv(2024).DOI: 10.48550/arxiv.2403.08819
Información de la revista: arXiv
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre investigación, innovación y enseñanza del MIT.
Citación:La técnica del 'termómetro' evita que un modelo de IA se confíe demasiado en las respuestas incorrectas (31 de julio de 2024)recuperado el 31 de julio de 2024de https://techxplore.com/news/2024-07-thermometer-technique-ai-overconfident-wrong.html
Este documento está sujeto a derechos de autor.Aparte de cualquier trato justo con fines de estudio o investigación privados, noparte puede ser reproducida sin el permiso por escrito.El contenido se proporciona únicamente con fines informativos.