La capacidad de Apple para crear modelos de IA increíblemente compactos pero potentes no tiene igual en la industria.manzana

Inteligencia de AppleEl equipo de investigación ha lanzado dos nuevos modelos de lenguaje pequeños pero de alto rendimiento utilizados para entrenar generadores de IA.El equipo de Machine Learning de Apple participa en un proyecto DataComp for Language Models de código abierto junto con otros miembros de la industria.
Se ha considerado que los dos modelos que Apple ha producido recientemente igualan o superan a otros modelos de entrenamiento líderes, como Llama 3 y Gemma.
Modelos de lenguaje como estos se utilizan para entrenar motores de inteligencia artificial, como ChatGPT, proporcionando un marco estándar.Esto incluye una arquitectura, parámetros y filtrado de conjuntos de datos para proporcionar datos de mayor calidad para que los utilicen los motores de IA.
Estoy muy emocionado de presentar DataComp for Language Models (DCLM), nuestro nuevo banco de pruebas para experimentos de conjuntos de datos controlados destinados a mejorar los modelos de lenguaje.1/xpic.twitter.com/uNe5mUJJxb
â Vaishaal Shankar (@Vaishaal)18 de junio de 2024
La presentación de Apple al proyecto incluye dos modelos: uno más grande con siete mil millones de parámetros y otro más pequeño con 1,4 mil millones de parámetros.El equipo de Apple dijo que el modelo más grande ha superado al modelo superior anterior, MAP-Neo, en un 6,6 por ciento en los puntos de referencia.
Más sorprendentemente, el modelo DataComp-LM del equipo de Apple utiliza un 40 por ciento menos de potencia informática para lograr esos puntos de referencia.Fue el modelo de mejor rendimiento entre aquellos con conjuntos de datos abiertos y competitivo frente a aquellos con conjuntos de datos privados.
Apple ha hecho que sus modelos sean completamente abiertos: el conjunto de datos, los modelos de peso y el código de entrenamiento están disponibles para que otros investigadores trabajen con ellos.Tanto el modelo más grande como el más pequeño obtuvieron puntuaciones lo suficientemente buenas en los puntos de referencia de comprensión masiva del lenguaje multitarea (MMLU) para ser competitivos frente a los modelos comerciales.
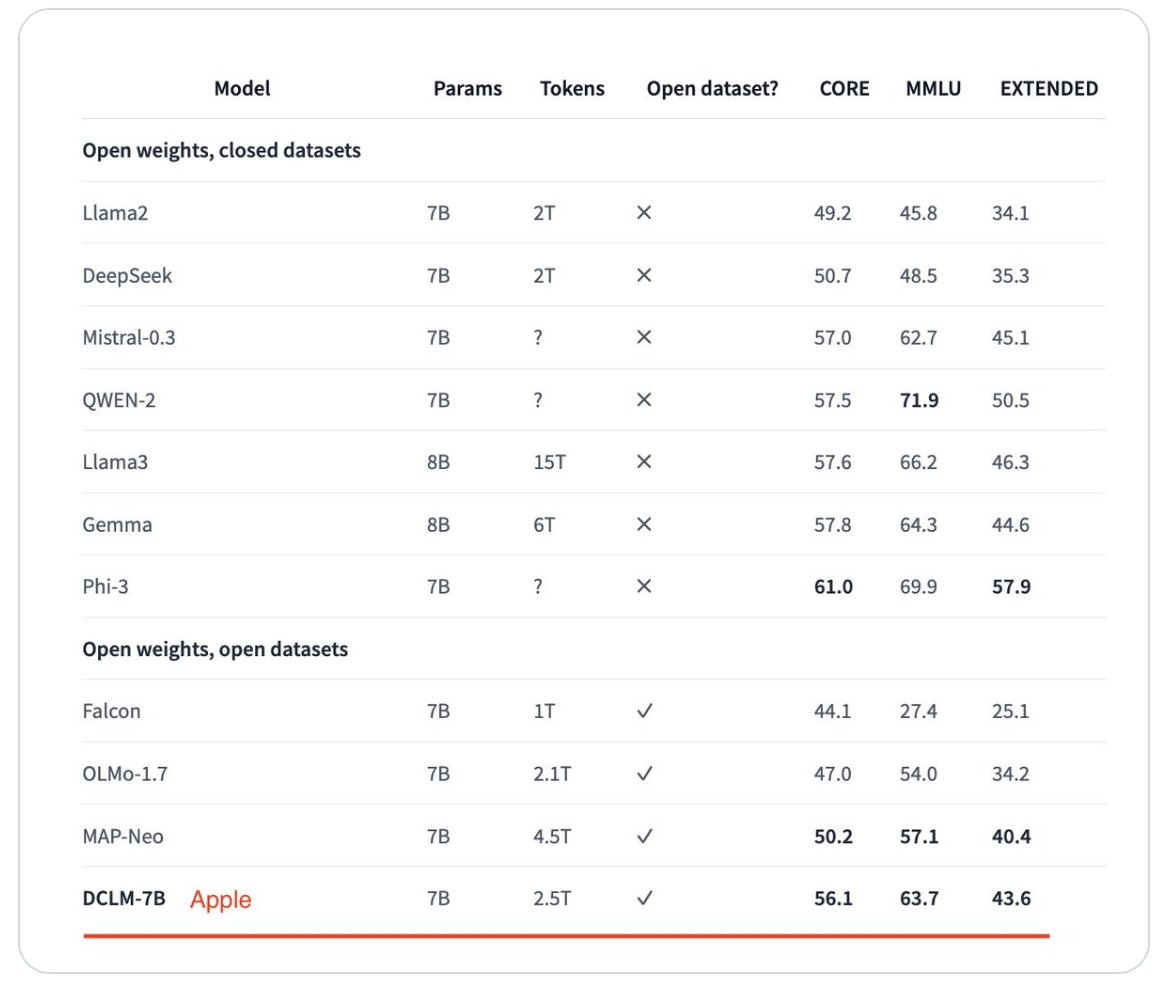
Los puntos de referencia para el conjunto de datos más grande de Apple resultan competitivos frente a otros modelos.
Al presentar Apple Intelligence y Private Cloud Compute en su conferencia WWDC en junio, la compañíacríticos silenciadosquien había afirmado que Apple estaba detrás de la industria en aplicaciones de inteligencia artificial en sus dispositivos.Los artículos de investigación del equipo de Machine Learning publicados antes y después de ese evento demostraron que la empresa es, de hecho, líder en la industria de la IA.
Estos modelos el equipo de Appleha liberadono están diseñados para su uso en ningún producto Apple futuro.Son proyectos de investigación comunitaria que muestran una mayor eficacia en la curación de conjuntos de datos pequeños o grandes utilizados para entrenar modelos de IA.
El equipo de aprendizaje automático de Apple ya habíainvestigación compartidaa la comunidad de IA en general.Los conjuntos de datos, notas de investigación y otros activos se pueden encontrar en HuggingFace.co, una plataforma dedicada a expandir la comunidad de IA.