. https://arxiv.org/abs/2403.05812")
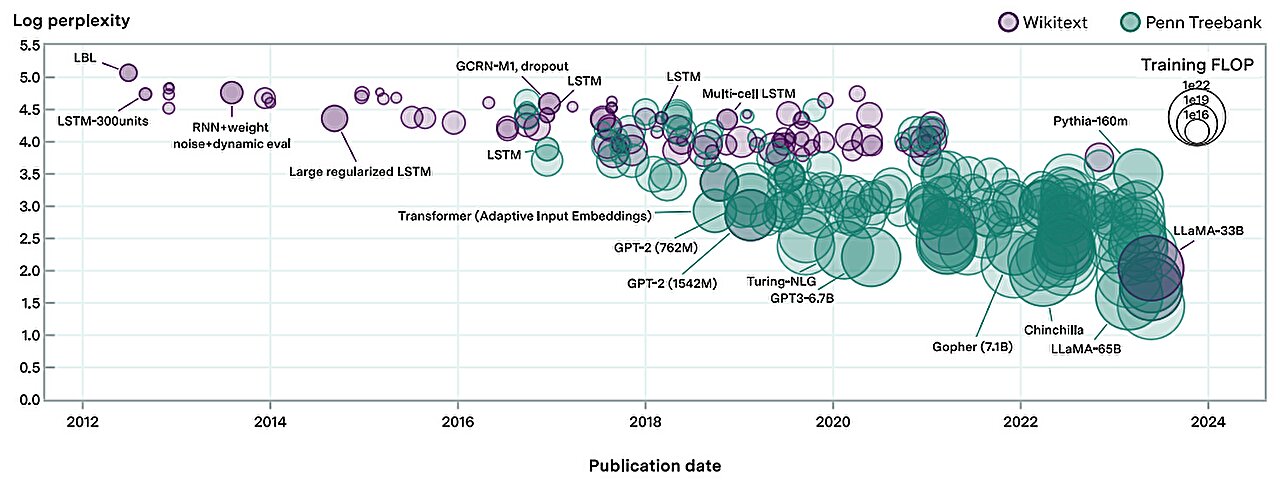
En 2012, los mejores modelos de lenguaje fueron pequeñas redes recurrentes que luchaban por formar oraciones coherentes.Un avance rápido hasta el día de hoy, y los grandes modelos de lenguaje como GPT-4 superan a la mayoría de los estudiantes en el SAT.¿Cómo ha sido posible este rápido progreso?
en unpapel nuevopublicado en elarXivservidor de preimpresión, investigadores de Epoch, MIT FutureTech y Northeastern University se propusieron arrojar luz sobre esta cuestión.Su investigación divide los impulsores del progreso en los modelos de lenguaje en dos factores: aumentar la cantidad de computación utilizada para entrenar modelos de lenguaje e innovaciones algorítmicas.Al hacerlo, realizan el análisis más extenso del progreso algorítmico en modelos de lenguaje hasta la fecha.
Sus hallazgos muestran que, debido a las mejoras algorítmicas, la computación necesaria para entrenar un modelo de lenguaje hasta un cierto nivel de rendimiento se ha reducido a la mitad aproximadamente cada ocho meses."Este resultado es crucial para comprender el progreso histórico y futuro de los modelos lingüísticos", afirma Anson Ho, uno de los dos autores principales del artículo."Si bien escalar la computación ha sido crucial, es sólo una parte del rompecabezas. Para obtener una imagen completa es necesario considerar también el progreso algorítmico".
La metodología del artículo está inspirada en las "leyes de escala neuronal": relaciones matemáticas que predicen el rendimiento del modelo de lenguaje dadas ciertas cantidades de computación, datos de entrenamiento o parámetros del modelo de lenguaje.Al compilar un conjunto de datos de más de 200 modelos de lenguaje desde 2012, los autores ajustaron una ley de escala neuronal modificada que tiene en cuenta las mejoras algorítmicas a lo largo del tiempo.
Con base en este modelo ajustado, los autores realizan un análisis de atribución de desempeño y descubren que escalar la computación ha sido más importante que las innovaciones algorítmicas para mejorar el desempeño en el modelado del lenguaje.De hecho, encuentran que la importancia relativa de las mejoras algorítmicas ha disminuido con el tiempo.
"Esto no implica necesariamente que las innovaciones algorítmicas se hayan ralentizado", afirma Tamay Besiroglu, quien también codirigió el artículo."Nuestra explicación preferida es que el progreso algorítmico se ha mantenido a un ritmo más o menos constante, pero la computación se ha ampliado sustancialmente, lo que hace que el primero parezca relativamente menos importante".
Los cálculos de los autores respaldan este marco, donde encuentran una aceleración en el crecimiento de la computación, pero no hay evidencia de una aceleración o desaceleración en las mejoras algorítmicas.
Al modificar ligeramente el modelo, también cuantificaron la importancia de una innovación clave en la historia del aprendizaje automático: el Transformer, que se ha convertido en la arquitectura de modelo de lenguaje dominante desde su introducción en 2017. Los autores encuentran que las ganancias de eficiencia ofrecidas por el Transformercorresponden a casi dos años de progreso algorítmico en el campo, lo que subraya la importancia de su invención.
Si bien es extenso, el estudio tiene varias limitaciones."Un problema recurrente que tuvimos fue la falta de datos de calidad, lo que puede dificultar el ajuste del modelo", dice Ho."Nuestro enfoque tampoco mide el progreso algorítmico en tareas posteriores como codificación y problemas matemáticos, para cuya ejecución se pueden ajustar los modelos de lenguaje".
A pesar de estas deficiencias, su trabajo es un gran paso adelante para comprender los impulsores del progreso en IA.Sus resultados ayudan a arrojar luz sobre cómo podrían desarrollarse los desarrollos futuros en IA, con importantes implicaciones para las políticas de IA.
"Este trabajo, dirigido por Anson y Tamay, tiene implicaciones importantes para la democratización de la IA", afirmó Neil Thompson, coautor y director del MIT FutureTech."Estas mejoras en la eficiencia significan que cada año niveles de rendimiento de la IA que estaban fuera de su alcance se vuelven accesibles para más usuarios".
"Los LLM han estado mejorando a un ritmo vertiginoso en los últimos años. Este documento presenta el análisis más exhaustivo hasta la fecha de las contribuciones relativas de las innovaciones algorítmicas y de hardware al progreso en el rendimiento de los LLM", dice el investigador de Open Philanthropy Lukas Finnveden, que no fueinvolucrados en el papel.
"Esta es una pregunta que me importa mucho, ya que informa directamente qué ritmo de progreso debemos esperar en el futuro, lo que ayudará a la sociedad a prepararse para estos avances. Los autores ajustan una serie de modelos estadísticos a un gran conjunto de datosde evaluaciones históricas de LLM y utilizan una validación cruzada extensa para seleccionar un modelo con un sólido rendimiento predictivo. También brindan una buena idea de cómo variarían los resultados bajo diferentes supuestos razonables, al realizar muchas comprobaciones de solidez.
"En general, los resultados sugieren que los aumentos en la computación han sido y seguirán siendo responsables de la mayor parte del progreso del LLM siempre que los presupuestos de computación sigan aumentando a una tasa de â¥4 veces por año. Sin embargo,algorítmicoEl progreso es significativo y podría representar la mayor parte del progreso si el ritmo del aumento de las inversiones se desacelera".
Más información:Anson Ho et al, Progreso algorítmico en modelos de lenguaje,arXiv(2024).arxiv.org/abs/2403.05812
Información de la revista: arXiv
Citación:De las redes recurrentes a GPT-4: medición del progreso algorítmico en modelos de lenguaje (2024, 13 de marzo)recuperado el 13 de marzo de 2024de https://techxplore.com/news/2024-03-recurrent-networks-gpt-algorithmic-language.html
Este documento está sujeto a derechos de autor.Aparte de cualquier trato justo con fines de estudio o investigación privados, noparte puede ser reproducida sin el permiso por escrito.El contenido se proporciona únicamente con fines informativos.