. DOI: 10.48550/arxiv.2402.03620")
Un equipo de investigadores de inteligencia artificial del proyecto DeepMind de Google, en colaboración con un colega de la Universidad del Sur de California, ha desarrollado un vehículo para permitir que los modelos de lenguaje grandes (LLM) encuentren y utilicen estructuras de razonamiento intrínsecas a las tareas como un medio para mejorar los resultados obtenidos.
El grupo ha escrito un artículo que describe su marco y describe qué tan bien se ha probado hasta ahora, y haal corrienteeso en elarXivservidor de preimpresión.También publicaron una copia del artículo en Hugging Face, unaprendizaje automáticoy plataforma de ciencia de datos.
Los grandes modelos de lenguaje, como ChatGPT, pueden devolver respuestas similares a las humanas a las consultas de los usuarios al buscar información en Internet y utilizarla para crear texto de forma humana, imitando cómo escriben los humanos.Pero estos modelos todavía tienen capacidades bastante limitadas debido a su naturaleza simple.En este nuevo estudio, los investigadores de DeepMind modificaron el modelo utilizado por los LLM para mejorar los resultados.
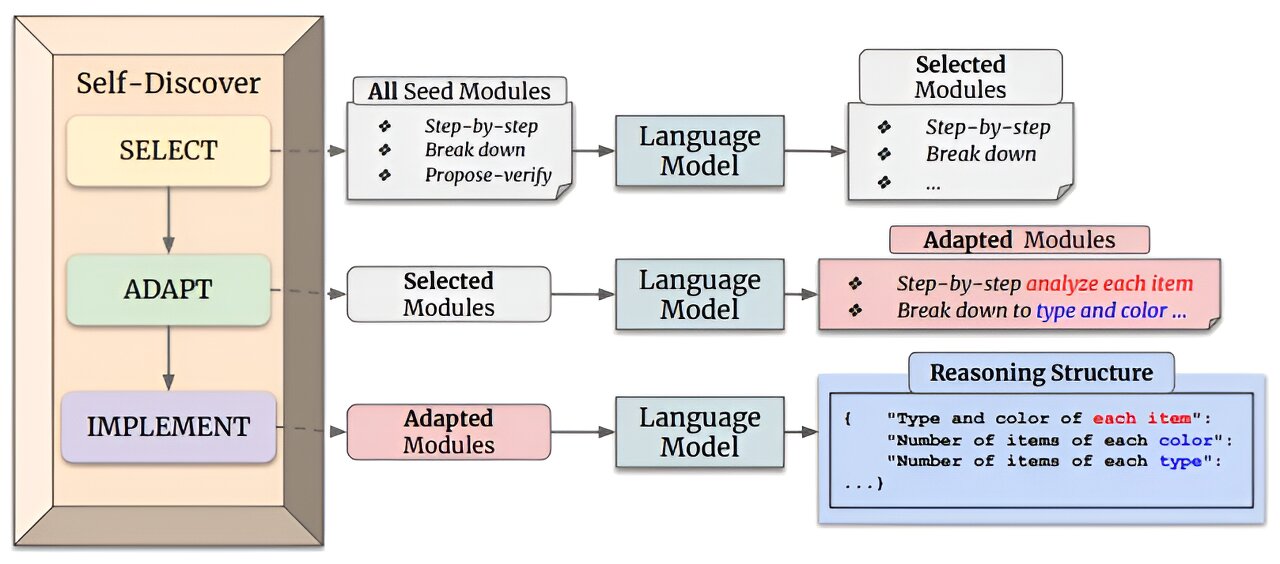
Para que los LLM tuvieran más con qué trabajar, el equipo de investigación les brindó un medio para participar en el autodescubrimiento copiando estrategias de resolución de problemas utilizadas por los humanos.Y lo hicieron dándoles la posibilidad de utilizarrazonamientomódulos que se han desarrollado a través de otros esfuerzos de investigación.Más específicamente, les dieron la posibilidad de hacer uso de módulos que permitenpensamiento críticoy/o análisis paso a paso de un problema en cuestión.Y eso permite a los LLM construir estructuras de razonamiento explícitas, en lugar de simplemente depender del razonamiento realizado por otros al crear sus documentos.
Para permitir dicho procesamiento, el equipo de investigación siguió un proceso de dos pasos.El primero implicó enseñar a un LLM cómo crear una estructura de razonamiento relacionada con una tarea determinada y luego hacer uso de un módulo de razonamiento apropiado.El segundo paso implicó permitir que el LLM siguiera un camino de autodescubrimiento que lo llevaría a la solución deseada.
Las pruebas del nuevo enfoque mostraron resultados muy mejorados: al usarlo con múltiples LLM, incluido GPT-4, y varias tareas de razonamiento bien conocidas, el enfoque de autodescubrimiento superó consistentemente al razonamiento de cadena de pensamiento y otros enfoques actuales por hastaal 32%.Los investigadores también descubrieron que mejoraba la eficiencia al reducir la computación de inferencia entre 10 y 40 veces.
Más información:Pei Zhou et al, Autodescubrimiento: modelos de lenguaje grandes autocomponen estructuras de razonamiento,arXiv(2024).DOI: 10.48550/arxiv.2402.03620
Información de la revista: arXiv
© 2024 Red Ciencia X
Citación:Un enfoque de autodescubrimiento: el marco DeepMind permite a los LLM encontrar y utilizar estructuras de razonamiento intrínsecas a las tareas (2024, 9 de febrero)recuperado el 9 de febrero de 2024de https://techxplore.com/news/2024-02-discovery-approach-deepmind-framework-llms.html
Este documento está sujeto a derechos de autor.Aparte de cualquier trato justo con fines de estudio o investigación privados, noparte puede ser reproducida sin el permiso por escrito.El contenido se proporciona únicamente con fines informativos.